不正取引検出のための機械学習プロジェクト
Fraud Detection with Machine Learning1. プロジェクト背景と目的
本プロジェクトは、実業務における不正取引(Fraud)検出を目的とした機械学習モデルの開発を行ったものである。
不正取引は発生頻度が極めて低く、かつ行動パターンが複雑で時間とともに変化するため、ルールベースや単一モデルでは安定した性能を得ることが難しい。
本プロジェクトでは、業務構造に基づいた特徴量設計、分人群モデリング戦略、およびアンサンブル手法を組み合わせることで、全体および重要なユーザー群における検出性能の向上を目指した。
2. データの特徴と課題
使用した取引データには、以下のような実務特有の課題が存在する。
- クラス不均衡:不正取引の割合が極めて低い
- 欠損値の存在:一部の特徴量は条件付きでのみ観測可能
- 時系列依存性:ユーザー・店舗の過去行動が現在の取引に強く影響
- ユーザー・店舗の異質性:新規ユーザーと既存ユーザー、店舗・地域ごとのリスク分布が大きく異なる
これらの特性を踏まえ、本プロジェクトではモデルの複雑化よりも適切なモデリング分割と特徴設計を重視した。
3. 特徴量エンジニアリング(Feature Engineering)
3.1 購入者(ユーザー)レベルの特徴
暗号化された Address 情報により購入者を一意に識別できるため、ユーザー単位での履歴分析が可能である。
基本方針:購入履歴の有無によるユーザー分割- 初回購入ユーザー(New User)
- 購入履歴を持つユーザー(Long-time User)
購入履歴を持つユーザーに対しては、以下の特徴量を構築した。
- 過去の購入回数
- 現在の購入デバイスと過去デバイスの一致性
- 現在の取引金額が過去平均からどの程度乖離しているか
- 行動パターンの変化を表す指標
これらは「行動の一貫性」を捉える特徴として、不正検出に有効である。
3.2 店舗(Merchant / Store)レベルの特徴
取引単位の情報に加え、店舗自体のリスク特性を表す特徴量を導入した。
- 店舗の過去不正取引率
- 歴史的な取引金額規模
store_device_diversity(使用デバイスの多様性)
これにより、店舗固有のリスク傾向をモデルに反映させた。
4. 分人群モデリング戦略(User Segmentation Modeling)
新規ユーザーと既存ユーザーでは、利用可能な情報量と行動の安定性が本質的に異なる。
そのため、本プロジェクトでは明示的な分人群モデリングを採用した。
4.1 モデリング方針
- 過去取引履歴に基づいてユーザーを分類
- 初回購入ユーザー / 購入履歴ユーザーでデータを分割
- 各人群ごとにモデル性能を評価
- 学習・検証は時間順を厳守し、情報漏洩(Time Leakage)を防止
5. モデル選択
以下のモデルを比較・検証した。
- CatBoost(主モデル)
- XGBoost
- Random Forest
- MLP / Transformer(検証目的)
欠損値処理、カテゴリ特徴の扱いやすさ、学習安定性を考慮し、最終的に CatBoost を中心に採用した。
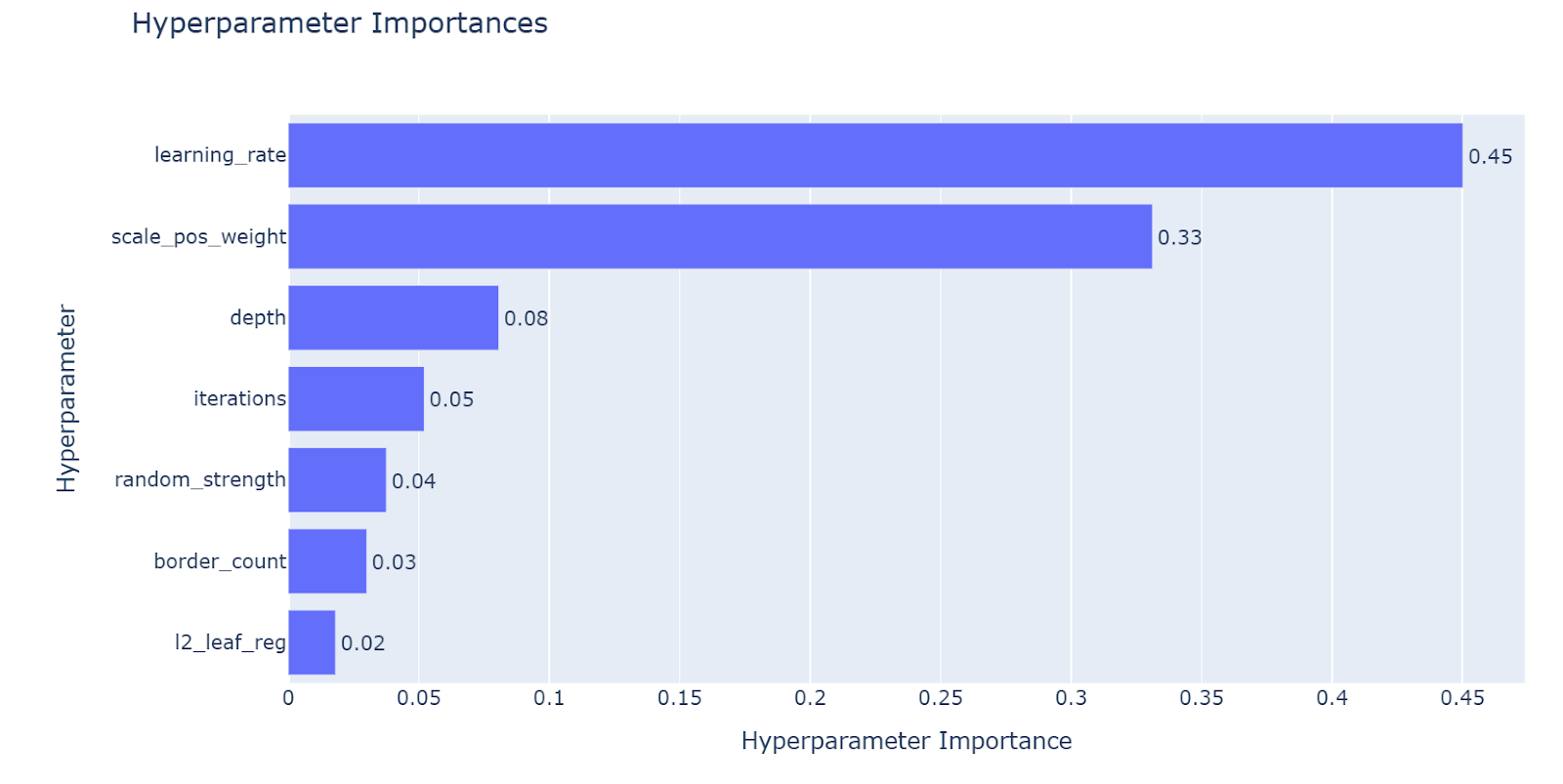
6. ハイパーパラメータ調整
CatBoost に対して系統的なハイパーパラメータチューニングを実施し、重要度分析を行った。
主な知見は以下の通り。
learning_rateが性能に最も大きく影響scale_pos_weightはクラス不均衡下での F1-score 改善に重要- 木の深さや反復回数は汎化性能と安定性に寄与
これにより、効率的かつ解釈可能なチューニング方針を確立した。
7. アンサンブル学習
単一モデルに加え、AutoGluon を用いたアンサンブルを実施。
- 複数モデルの予測を自動統合
- モデルの頑健性向上
- 最終性能評価の比較対象として活用
8. 実験結果(F1-score)
8.1 全体モデル
- F1 score:0.31 → 0.50
8.2 分人群別結果
| ユーザー種別 | 改善前 | 改善後 |
|---|---|---|
| 購入履歴あり | 0.44 | 0.60 |
| 購入履歴なし | 0.18 | 0.30 |
結果より、以下が確認できた。
- 履歴特徴は不正取引検出において極めて重要
- 新規ユーザーは依然として難易度が高いが、分人群モデリングにより改善
- 全体指標だけでなく人群別評価が業務価値を正しく反映する
9. まとめ
本プロジェクトでは、
- 業務仮説に基づく特徴量設計
- 不均衡データを前提としたモデリング戦略
- 新規 / 既存ユーザーの分人群モデリング
- CatBoost とアンサンブルによる安定した学習
を組み合わせることで、実務適用可能な不正取引検出モデルを構築した。
本手法は、店舗別・地域別・時間帯別などへの拡張も容易である。