Project Name: Kita – Kitakyushu City Smart Waste Sorting Q&A System
Project Type: RAG (Retrieval-Augmented Generation) Question Answering System
Development Period: GMO Internship Project
Team Size: 3 members (Sota Aoki, Hanyang Yin, Taro Yasuda)
My Role: [Please describe your specific role and responsibilities]
Background and Objectives
Business Challenges
Waste sorting rules in Kitakyushu City are complex, making it difficult for users to quickly obtain accurate information
Garbage collection days differ by neighborhood, making searches inconvenient
Existing search methods are inefficient and provide a poor user experience
Solution
We developed a smart Q&A system based on a RAG architecture that provides the following through natural language interaction:
Search for waste sorting rules
Lookup of garbage collection days by town name
Extensible custom knowledge base functionality
System Architecture Design
Technology Stack Selection
Frontend Layer
Streamlit: Rapid development of an interactive web UI
GPU Monitoring: Real-time resource usage display via NVML / nvidia-smi
Backend Layer
FastAPI: Asynchronous API framework supporting high concurrency
Business Layer (FastAPI): API routing, RAG orchestration, data validation
Data Layer (ChromaDB): Waste rules, area information, user knowledge base
User Interface
Text-based Query Interface
The system provides an intuitive chat interface where users can ask questions in natural language about waste sorting and collection schedules.
Text-based query interface showing natural language Q&A interaction
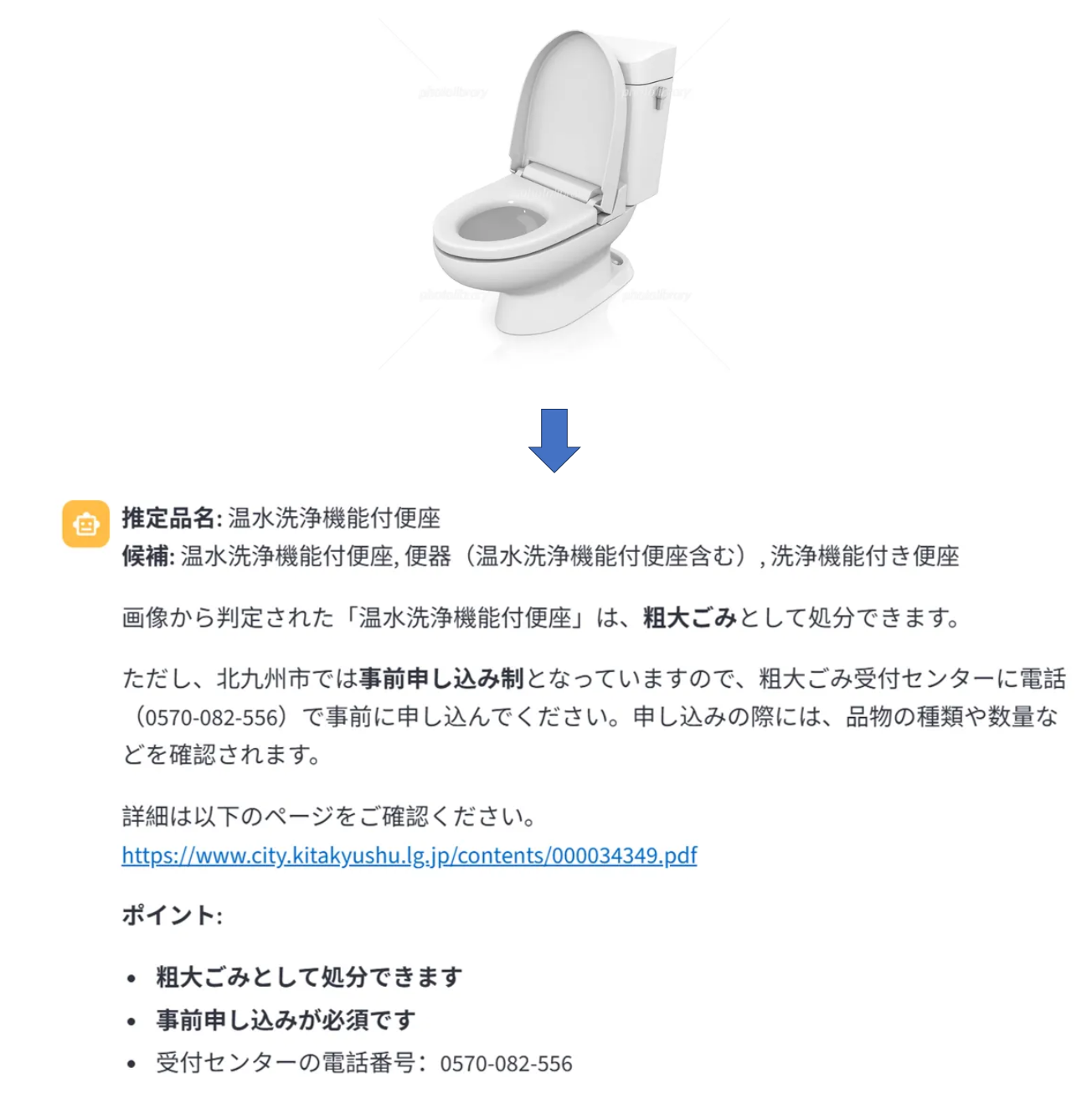
Image-based Query Interface
Users can also upload images of items they want to dispose of, and the system will identify the item and provide appropriate disposal instructions.
Image-based query interface with visual item recognition
Core Technical Innovations
1. Hybrid Grounding System v2.0 (Key Technology)
Problem: Traditional MeCab tokenization lacks accuracy for complex queries
Innovative Solution: A three-layer intelligent recognition system
Layer 1: Exact Match
Full match with database → confidence 1.0 → immediate response
Response time < 5 ms
Layer 2: Smart Routing (Path Selection)
if input_length < 20:
→ Path A (Fast Path): Global embedding search
→ Response time < 300 ms
else:
→ Path A + Path B (Dual Path):
- Path A: Global semantic search
- Path B: LLM-assisted phrase extraction + segmented search
→ Response time < 600 ms
Layer 3: Confidence Evaluation
* High (≥ 0.70): Direct adoption
* Medium (0.45–0.70): Presented to user
* Low (< 0.45): Automatic fallback to MeCab
Results
* Accuracy improvement: 78% → 92%
* Average response time: < 400 ms
* Automatic fault tolerance via fallback mechanisms
2. Streaming Response Optimization
Problem: Blocking responses caused long wait times and poor UX
Solution:
* Implemented Server-Sent Events (SSE) for streaming responses
* Token-by-token output with Time to First Byte (TTFB) < 1s